 Por Alex G. Barreto M. y Sonia Margarita Amores [*]
Por Alex G. Barreto M. y Sonia Margarita Amores [*]
Bogotá, 2012.
Secciones: Artículos, lingüística / interpretación / nuevas tecnologías
Abstract
La Universidad Pedagógica Nacional en el marco del proyecto Manos y Pensamiento ha contratado y gestionado la prestación del servicio de interpretación de lengua de señas colombiana – español, como parte de la estrategia para facilitar la inclusión de estudiantes Sordos a la vida universitaria. Una de las Mesas de Investigación generadas al interior del equipo de intérpretes de la Universidad, ha explorado la posibilidad de usar el software ELAN como herramienta para analizar la interpretación en el contexto universitario. En el presente artículo, se presentan los resultados del proyecto piloto propuesto por la Mesa ELAN y se esbozan algunas potencialidades y proyecciones que pudiera tener un proyecto de investigación de la lengua de señas y su interpretación al interior de la Universidad utilizando dicho software.
The National Pedagogic University in the framework of Hands and Thought project has hired and managed the Colombian Sign Language – Spanish interpreters as part of strategy to bring Deaf student inclusion to the mainstream within University. One of the research groups arose within interpreters’ team has explored possibilities to use ELAN software as a tool to analyze interpretation in the University settings. In this paper, we present outcomes of pilot project proposed for ELAN research group and we outline some potentialities and projections that a Sign Language and its interpreting project could have within University using ELAN software.
Introducción
La interpretación en lengua de señas en Colombia ha tenido avances significativos en los últimos 15 años en la medida que ha sido reconocida como labor remunerada en múltiples contextos. Dichos avances han estado ligados estrechamente con el acceso de los Sordos[1] a la educación en todos los niveles.
En el presente artículo nos referiremos a la interpretación de lengua de señas en contextos universitarios. La mediación comunicativa en dichos contextos ha planteado retos nunca antes enfrentados por los intérpretes de lengua de señas (en adelante ILS), toda vez que, de forma específica, la academia ha demandado la interpretación de textos y discursos técnicos-científicos con un alto nivel de complejidad en términos de léxico y estructura gramatical. La Universidad Pedagógica Nacional, mediante su proyecto de inclusión de estudiantes Sordos a la vida universitaria, ha tenido la oportunidad de liderar el desarrollo de la interpretación en el país al auspiciar una cantidad considerable de intérpretes en el contexto universitario semestre a semestre durante casi una década como uno de los variados ajustes razonables para facilitar la inclusión educativa de las personas Sordas.
En el siguiente documento se presentan los resultados del pilotaje de la Mesa de Trabajo del equipo de interpretación de la UPN, titulada ELAN que surgió como un ejercicio aplicación de los estudios descriptivos de la traducción e interpretación a una situación-problema especifica del contexto de la educación superior: el análisis preciso y detallado de corpus de interpretación de lengua de señas asistida por un software. (Cfr. Baker, 2004; Crasborn, O., Sloetjes, H., 2008).
El proyecto Manos y Pensamiento
El proyecto Manos y Pensamiento: Inclusión de estudiantes sordos a la vida universitaria, surgió como una respuesta al ingreso de estudiantes Sordos a la Universidad Pedagógica Nacional en el año 2003, y desde entonces ha orientado y liderado el acceso y permanencia de estudiantes Sordos en el ejercicio de las distintas ramas de la carrera docente.
Como educadora de educadores, la universidad ha facilitado los procesos formativos de 260 estudiantes Sordos en 11 de sus programas (Licenciaturas en Educación Física, Matemáticas, Sociales, Artes Visuales, Diseño Tecnológico, Educación Infantil, Educación Especial, Psicopedagogía, Educación Comunitaria con Énfasis en Derechos Humanos, Biología y Lenguas). Los intérpretes contratados por la universidad bajo la interventoría de Manos y Pensamiento, suplen la demanda de interacción comunicativa e intercultural en todas las facultades de la universidad, lo cual ha significado que el ejercicio de interpretación se dinamice al interior del esquema conceptual y terminológico de varios campos del conocimiento. Este asunto, ha representado retos adicionales a la formación, cualificación y evaluación de intérpretes, ya que ha demandado el diseño, uso e implementación de instrumentos confiables para hacer el seguimiento a los procesos de interpretación LSC – español y español– LSC, procesos que impactan la calidad de la educación de los maestros Sordos en formación.
En aras de aunar esfuerzos para generar estrategias e instrumentos que contribuyan a tener una comprensión más amplia del ejercicio de interpretación, al interior del equipo de ILS se han creado Mesas de Trabajo que pretenden indagar diversos aspectos de la interpretación. La mesa ELAN en su fase de contextualización ha buscado preliminarmente herramientas que puedan ser útiles en la descripción de los procesos de interpretación de lengua de señas. Si se pueden describir con precisión dichos fenómenos, se abre una puerta llena de posibilidades para analizar, evaluar e investigar la interpretación de lengua de señas.
El software ELAN[2]
El software de transcripción multimodal fue diseñado y creado originalmente por Birgit Hellwigen el Max Planck Institute for Psycholinguistics, de Nijmegen,(Holanda). La herramienta permite realizar y procesar anotaciones en líneas digitales de información (tiers), para distintos tipos de archivos de audios y videos con información lingüística.
Sus utilidades y desarrollos han sido citados en por lo menos los artículos y documentos de la tabla 1.
Tabla 1
| Brugman, H., Russel, A. (2004). Annotating Multimedia/ Multi-modal resources with ELAN. In: Proceedings of LREC 2004, Fourth International Conference on Language Resources and Evaluation.Wittenburg, P., Brugman, H., Russel, A., Klassmann, A., Sloetjes, H. (2006). ELAN: a Professional Framework for Multimodality Research. In: Proceedings of LREC 2006, Fifth International Conference on Language Resources and Evaluation.Sloetjes, H., & Wittenburg, P. (2008). Annotation by category – ELAN and ISO DCR. In: Proceedings of the 6th International Conference on Language Resources and Evaluation (LREC 2008). |
Crasborn, O., Sloetjes, H. (2008). Enhanced ELAN functionality for sign language corpora. In: Proceedings of LREC 2008, Sixth International Conference on Language Resources and Evaluation.Lausberg, H., & Sloetjes, H. (2009). Coding gestural behavior with the NEUROGES-ELAN system. Behavior Research Methods, Instruments, & Computers, 41(3), 841-849. doi:10.3758/BRM.41.3.591. |
Leyenda tabla 1: Algunas investigaciones que han citado al ELAN.
Mesa de Trabajo ELAN (Proyecto Piloto 2011-I y 2011-II)
La Mesa ELAN, surgió como un proyecto piloto encaminado a contribuir al mejoramiento de los servicios de interpretación de la UPN a través de la descripción de procesos de interpretación. Dicha mesa desarrolló durante el 2011 una fase de contextualización en la que intentó establecer qué herramientas y medios podrían ser los más eficaces para describir la interpretación en contextos universitarios. Después de reformular reiteradamente los objetivos y la denominación de la mesa, se inició con la exploración del software ELAN en la descripción de textos de lengua de señas colombiana interpretados simultáneamente al castellano hablado.
La pregunta de investigación fue: ¿Es útil el software ELAN en la descripción de situaciones de interpretación de lengua de señas en el contexto académico, de modo que pueda arrojar datos significativos para el mejoramiento de dicha actividad de mediación comunicativa?
De forma preliminar se persiguieron dos objetivos específicos:
Mostrar la pertinencia del ELAN en la transcripción de fragmentos reales de interpretación de lengua de señas, y
Comparar los datos que arroja la matriz del programa en dos variables concretas: Velocidad en términos de Señas/ Minuto, Palabras/Minuto y duración de decalage[3]con algunas de las investigaciones realizadas en el campo (i.e. Cokely (1992) Russell (2002)).
Se escogió la dirección LSC a castellano, por dos razones. En primer lugar, dicha dirección en la interpretación permite obtener textos en la primera lengua de los informantes Sordos (la LSC) e intérpretes (el castellano). Segundo, este orden en la producción no ha sido investigado tan extensamente como el sentido lengua oral a lengua de señas que parece ser el más usual en contextos especializados, espacios en donde muchas veces los Sordos permanecen como agentes pasivos, receptores de información. Dado que el contexto universitario demanda la participación activa de los maestros en formación, la producción del intérprete en su primera lengua juega un papel relevante que se priorizó en el presente análisis, sin escatimar, por supuesto, la importancia de la dirección castellano a lengua de señas.
Es importante tener presente que todas las interpretaciones son distintas debido al contexto donde se desarrollan. El modelo descriptivo de la interpretación presentado por Dennis Cokely (1992), fue desarrollado a partir de interpretación de conferencias en la dirección inglés a lengua de señas americana (ASL) y el estudio de Russell (2002) en simulaciones de contextos judiciales. La Mesa de Trabajos se interesó en la posibilidad de describir interpretaciones en la dirección LSC a español hablado, concentrándose en los tiempos de desfase (decalage) y en la velocidad de los textos orales utilizados por los intérpretes de lengua de señas y oradores Sordos/oyentes para contextos universitarios. La descripción lingüística demostró que existen segmentos léxicos en la lengua de señas con una duración de 192 milésimas de segundo (menos de lo que dura un parpadeo) (ver imagen 1, 2 y 3). Este hecho evidencia la necesidad de establecer un instrumento que permita detectar estas mínimas variaciones lingüísticas para tener insumos concretos y específicos que aporten al análisis sobre el desempeño del intérprete.

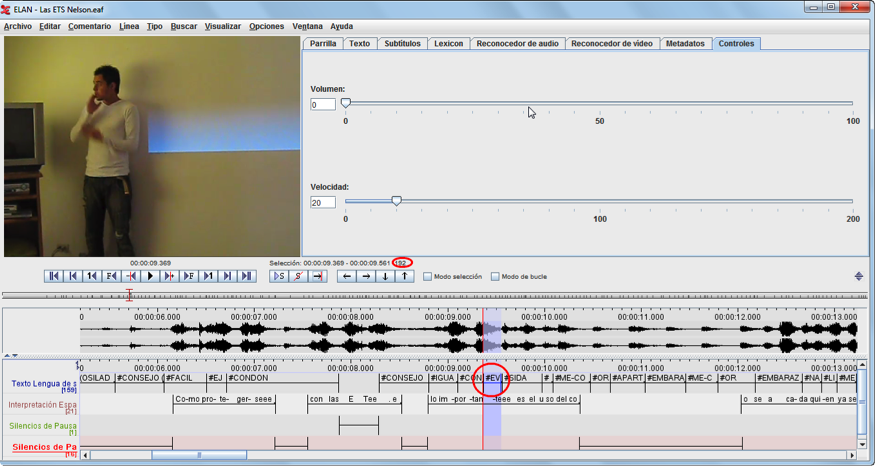
![Leyenda Imagen 3: La seña evitar[4]se ejecuta en 192 milésimas de segundo, más rápido de lo que dura un parpadeo en promedio (200 ms)](https://cultura-sorda.org/wp-content/uploads/2015/06/Barreto-Amores3.png)
La transcripción de discursos en lengua de señas es una labor ardua para el observador a simple vista. Por tal razón, el software ELAN se vislumbra como una herramienta tecnológica idónea para dicho trabajo. Su arquitectura informática permite en una misma interface articular y gestionar archivos de video y de audio de modo que puedan realizarse transcripciones escritas en una línea de tiempo, subdividida en milisegundos o fotogramas, según la necesidad del investigador.
Es importante aclarar que el nivel exploratorio de la Mesa de Trabajo, en su carácter de proyecto piloto, no permitió tener los recursos disponibles para analizar la complejidad de los discursos en lengua de señas con rigor. El desarrollo del proyecto permitió develar la complejidad del análisis y puso de manifiesto la necesidad de desarrollar un proyecto amplio y continuado que permita arrojar datos estadísticamente precisos.
Metodología
Para realizar la exploración del ELAN en la descripción de interpretaciones, se tomaron cinco muestras; una de un discurso en lengua de señas diplomático, dos simuladas y dos de situaciones reales de interpretación. La muestra del discurso en lengua de señas diplomático en señas internacionales (IS) fue tomado de la bienvenida del entonces presidente de la Federación Mundial de Sordos, en el sitio web www.wfdeaf.org. En las muestras simuladas, se les solicitó a algunos estudiantes Sordos que espontáneamente hablaran de algún tema académico y se les informó que se grabaría la interpretación simultánea en español para un trabajo de investigación[5]. Las muestras de situaciones reales de interpretación, fueron facilitadas con la autorización de los docentes universitarios quienes permitieron que realizaran grabaciones del servicio de interpretación provisto. Las siguientes son las características técnicas de las muestras:
Tabla 2
| Muestra 1 (Experiencia Nocturna) | ||
| Duración: | 2 minutos, 43 Segundos | |
| Modalidad: | Fragmento Servicio de interpretación Real | |
| Contexto: | Curso de Proyecto de Vida y Orientación vocacional (Semestre 0) | |
| Dirección: | Castellano a LSC | |
| Muestra 2 (Las ETS) | ||
| Duración: | 1 minuto | |
| Modalidad: | Fragmento Servicio de interpretación Real | |
| Contexto: | Curso Castellano como segunda lengua (Semestre 0) | |
| Dirección: | LSC a Castellano | |
| Muestra 3 (Presentación experiencia UPN) | ||
| Duración: | 1 minutos, 3 Segundos | |
| Modalidad: | Simulación Elicitada | |
| Contexto: | Preparación de servicio | |
| Dirección: | Castellano a LSC | |
| Muestra 4 (Qué es el arte) | ||
| Duración: | 1 minutos, 1 Segundos | |
| Modalidad: | Simulación Elicitada | |
| Contexto: | Preparación de servicio | |
| Dirección: | Castellano a LSC | |
| Muestra 5 (Presentación nueva Web (WFD) | ||
| Duración: | 1 minutos, | |
| Modalidad: | Monólogo para web | |
| Contexto: | Texto Señas internacionales (IS) | |
| Señante: | Markku Jokinen (Presidente del WFD) | |
Leyenda tabla 2: Características técnicas de las muestras
Recolección de Muestras
Se adaptó la técnica de recolección de Cokely (1992) a los recursos y tiempos de la mesa de trabajo.
Se filmaron secciones de interpretación, con una duración de uno a diez minutos.
En las muestras de más de un minuto, se escogió un minuto al azar para transcribir (Muestras 2, 3 y 5). Como la muestra 4, tenía la duración de 1 minuto y 1 segundo, se transcribió intacta.
La muestra 1 se descartó para el análisis ya que dicho video presentaba la interpretación en la dirección castellano a LSC distinta a la dirección de interpretación objeto de la exploración de la Mesa, LSC a castellano. Por otro lado, no se incluyó dicha muestra en el análisis debido a las características particulares que presentó el texto cuando fue enunciado (el relato fue leído con muchas pausas y con una entonación que difiere de los normalmente usados). Como dichas características prosódicas hubieran podido alterar los datos del análisis, se transcribió sólo como información de referencia la totalidad de la muestra 1 (2 minutos y 43 segundos). Dicho tiempo correspondió a la unidad discursiva interpretada (el microrrelato Experiencia Nocturna).
Para iniciar la transcripción en el ELAN se introdujeron las siguientes líneas a la matriz:
- mensaje en Castellano/Interpretación en Castellano,
- mensaje en LS/interpretación en LS
- silencios en Castellanos
- silencios en Lengua de señas
- decalage
- recuperación
Cada línea matriz permitía anotar valores en segmentos de duración de tiempo (líneas iii, iv, v, vi) y contenidos específicos (líneas i y ii), como es el caso de los segmentos léxicos en LSC (Señas-palabra, señas-frase) o los segmentos léxicos en castellano (palabras).
Una vez transcritas las muestras se construyeron tablas con un recuento de los aspectos cuantitativos de las muestras, y otras con un compilado con la duración de los textos en LSC y los tiempos de decalage. Los datos deben ser entendidos en el marco las variables internas y externas que afectan el proceso de interpretación (velocidad de los mensajes LS/LO, experiencia del intérprete en interpretación, aprendizaje de la lengua de señas del intérprete, nivel de formación académica del intérprete, tipología discursiva del texto interpretado etc.), lo cual en este ejercicio hace difícil hacer generalizaciones concluyentes.
La información fue socializada con el equipo de intérpretes de lengua de señas de la Universidad.
Propuesta de análisis preliminar de la interpretación (lengua de señas – español) a través del ELAN
Un modelo para la comprensión de la interpretación de lengua de señas.
Nuestra propuesta de análisis preliminar se enmarca en el modelo cognitivo de la interpretación propuesto por Dennis Cokely para la lengua de señas norteamericana (ASL), publicado en Interpretation: A sociolinguistic model(1992).
Dicho modelo denominado ‘sociolingüístico’ por la consideración general que hace sobre las variables sociales y discursivas que inciden en el desarrollo de la interpretación, retoma el esquema básico propuesto por Seleskovitch (Seleskovitch, 1978) y las investigaciones en interpretación simultánea que iniciaron a mediados de los años 70’s e inicios de los 80’s. El modelo es el resultado de la tesis doctoral de Dennis Cokely, un lingüista de la lengua de señas y conocedor de la comunidad sorda por sus años de trabajo en la Universidad de Gallaudet y como presidente (1983 -1987) del RID, el Registro de Intérpretes para Sordos de Estados Unidos. Aunque en la actualidad existen otros modelos y amplios desarrollos en investigación en interpretación de lengua de señas (Russell, 2002; Napier, 2002; Wilcox & Shaffer, 2005; Napier, 2009; Brunson, 2011; Janzen, 2005) decidimos basarnos en la propuesta de Cokely (1992) por ser la más conocida en el país y una de las más completas en el análisis del decalage.
El modelo define siete procesos cognitivos en el proceso de interpretación de lengua de señas con implicaciones y subprocesos sociolingüísticos[6] según se muestra en la tabla 4. Los pasos son muy similares a los planteados por Seleskovitch (1978).
Tabla 4
| (1) | (2) | (3) | (4) | (5) | (6) | (7) |
| Recepción del mensaje | Procesamiento preliminar | Retención de la memoria a corto plazo | Intento semántico realizado | Equivalenciasemántica determinada | Formulación Sintáctica del mensaje | Producción del mensaje |
Leyenda tabla 4: Modelo sociolingüístico de procesamiento de la interpretación simplificado (Cokely, 1992).
Adicionalmente, la investigación determina cinco tipologías principales de errores (miscues) en la interpretación: omisiones, adiciones, sustituciones, intrusiones y anomalías. Las omisiones, en particular, han recibido tratamiento en investigaciones posteriores (Napier, 2002) (Cerney, 2005) (Leeson, 2005), ya que en muchas ocasiones no responden a equivocaciones del intérprete sino a estrategias lingüísticas de interacción en el discurso (linguistic coping strategy).
Para su investigación, Cokely escogió a seis intérpretes como informantes con las características mostradas en la tabla 4.
Tabla 4
| Int. 1 | Int. 2 | Int. 3 | Int. 4 | Int. 5 | Int. 6 | |
| Género | M | F | M | F | F | M |
| Edad | 30+ | 30+ | 25+ | 35+ | 35+ | 35+ |
| Padres | PS | PS | PS | PO | PO | PO |
| Años señando | 31 | 33 | 26 | 21 | 11 | 14 |
| Años interpretando | 11 | 18 | 8 | 16 | 10 | 10 |
| Años certificado-RID | 9 | 11 | 7 | 10 | 3 | 10 |
| Nivel Educativo | pregrado | maestría | pregrado | pregrado | maestría | maestría |
Leyenda tabla 4: Características de los informantes de la investigación Cokely (1992).
Los informantes fueron filmados durante un congreso de interpretación de lengua de señas, con una cámara profesional e iluminación y sonido idóneos. Algunas características del muestreo fueron las siguientes: En el evento en cuestión los intérpretes transmitieron temas “familiares” expuestos por expertos relacionados con su labor. El auditorio estaba compuesto por intérpretes y personas Sordas y el discurso fue tipo monólogo-magistral. De toda la grabación, se extrajeron secciones de video de un promedio de treinta minutos por intérprete, de los cuales fueron seleccionados para el análisis y al azar el minuto cinco de cada cinco minutos. Una vez seleccionado el material, hablantes monolingües de ambas lenguas realizaron la respectiva transcripción, además de una provisional retro-traducción (traducción del producto de interpretación de la muestra).
Los antecedentes teóricos de la tesis, son recopilados por el autor en el primer capítulo. De las fuentes, es importante resaltar algunos datos para la presente consideración:
Observaciones tempranas (Paneth, 1957) señalaron la diferencia de retraso (decalage) entre TO y TT en el desempeño de los intérpretes: de 2 a 4 segundos.
Gerver (1967) demostró que el aumento de la tasa de velocidad del discurso hablado disminuía la efectividad de la interpretación. Para esto filmó el mismo segmento de discurso e hizo interpretarlo sistemáticamente a diferentes velocidades (95, 112, 120, 142 y 164 palabras por minuto)
Seleskovitch (1978) confirmo los datos de Gerver (1976) al determinar que la velocidad óptima para interpretar se suscribía de 95 a 120 palabras por minuto.
Es interesante resaltar que las investigaciones que contextualizaron la propuesta de Cokely, realizadas hace más de 35 años, no tuvieron en cuenta las interpretaciones en lengua de señas, aspecto que situaba el modelo de dicho lingüista de la lengua de señas como “innovador” hace 20 años. Las conclusiones de Cokely corroboran las precedentes y añaden un aspecto relevante: los intérpretes que tienen los decalage más largos (4,8 segundos, en promedio) son los más precisos (se equivocan menos). Lo anterior queda patente en la tabla 5.
Tabla 5
| Int. 1 | Int. 2 | Int. 3 | Int. 4 | Int. 5 | Int. 6 | |
| Total muestra Min. | 34 | 19 | 30 | 44 | 22 | 27 |
| Rangodecalage en Seg. | 1-5 | 1-6 | 1-4 | 1-6 | 1-6 | 4-8 |
| Promedio decalage Seg. | 2,4 | 3 | 1,7 | 2,4 | 2,7 | 4,8 |
| Total de errores | 139 | 42 | 135 | 96 | 65 | 20 |
Leyenda tabla 5: Características de los informantes de la investigación de Cokely (1992)
Tendencias de las muestras del presente estudio.
La transcripción en el ELAN permitió observar comportamientos particulares de los textos en lengua de señas y sus interpretaciones en lengua castellana hablada. A continuación, presentamos los datos cuantitativos arrojados por los textos en LSC. Los “segmentos léxicos” en LSC corresponden a señas-palabra/señas-frase[7], y en castellano corresponden a palabras.
| Tabla 6 | ||||||
| Muestra 2 | ||||||
| Línea | Número de segmentosléxicos/min. | Duración mínima | Duración máxima | Promedio de duración | Duración total de comentario | Porcentaje de duración del comentario |
| Texto LSC | 159 | 0,114 | 1,675 | 0,380 | 60,414 | 95% |
| Interpretación Castellano | 190 | 0,006 | 5,094 | 2,281 | 47,894 | 75% |
| Silencios LSC | 1 | 0,407 | 0,407 | 0,407 | 0,407 | 1% |
| Silencios castellano | 16 | 0,186 | 3,220 | 0,780 | 12,480 | 20% |
| Decalage | 13 | 0,655 | 4,890 | 2,693 | 35,004 | 55% |
| Recuperación | 1 | 6,760 | 6,760 | 6,760 | 6,760 | 11% |
| Muestra 4 | ||||||
| Línea | Número de segmentos léxicos/min. | Duración mínima | Duración máxima | Promedio de duración | Duración total de comentario | Porcentaje de duración del comentario |
| Interpretación Castellano | 127 | 0,674 | 6,114 | 2,650 | 42,399 | 70% |
| Texto LSC | 102 | 0,001 | 1,287 | 0,521 | 53,133 | 87% |
| Silencios Castellano | 14 | 0,495 | 1,970 | 0,954 | 13,360 | 22% |
| Silencios LSC | 1 | 0,245 | 0,245 | 0,245 | 0,245 | 0% |
| Decalage | 15 | 1,440 | 4,371 | 2,610 | 39,151 | 64% |
| Recuperación | 1 | 8,626 | 8,626 | 8,626 | 8,626 | 14% |
| Muestra 3 | ||||||
| Línea | Número de segmentos léxicos/min. | Duración mínima | Duración máxima | Promedio de duración | Duración total de comentario | Porcentaje de duración del comentario |
| Interpretación castellano | 114 | 0,005 | 5,995 | 3,023 | 39,294 | 62,076 |
| Silencios castellano | 11 | 0,425 | 6,447 | 1,706 | 18,762 | 29,640 |
| Texto LSC | 130 | 0,099 | 2,686 | 0,415 | 54,007 | 85,319 |
| Silencios de Pausa Señas | 3 | 0,595 | 5,288 | 2,191 | 6,573 | 10,384 |
| Decalage | 11 | 1,31 | 5,765 | 3,550 | 39,045 | 61,682 |
| Recuperación | – | – | – | – | – | – |
Leyenda tabla 6: Datos cuantitativos Muestras 2, 3 y 4
Como el proyecto pretende develar los comportamientos discursivos de la interpretación en contextos académicos, se realizó una comparación de los textos expositivos de las muestras con un texto expositivo diplomático internacional. Por supuesto, son se pretende sugerir que los discursos en la universidad deberían comportarse como tales discursos diplomáticos. La muestra 5 sólo se toma como punto de referencia, asumiendo que dicha muestra se comporta como un estándar del discurso expositivo[8].
| Tabla 7 | ||||||
| Muestra 5 (referencia) | ||||||
| Línea | Número de Señas/min | Duración mínima | Duración máxima | Promedio de duración | Duración total de comentario | Porcentaje de duración del comentario |
| WFD Sign | 82 | 0,180 | 1,588 | 0,659 | 54,042 | 90% |
| Silencios Señas | 7 | 0,335 | 1,460 | 0,756 | 5,290 | 9% |
| Textos en Lengua Señas | ||||||
| Línea | Número de Señas/min | Duración mínima | Duración máxima | Promedio de duración | Duración total de comentario | Porcentaje de duración del comentario |
| Muestra 4 | 101 | 0,526 | 0,600 | 0,559 | 53,132 | 87% |
| Muestra 2 | 159 | 0,374 | 0,429 | 0,399 | 60,414 | 95% |
| Muestra 3 | 130 | 0,431 | 0,491 | 0,456 | 54,007 | 85% |
Leyenda tabla 7: Datos cuantitativos de los textos en lengua de señas.
Como el valor del decalage es variable a través de cada segundo de las muestras, se tomaron como referencia las muestras de decalage del inicio de cada enunciado de los textos en lengua de señas.
Tabla 8
| Línea | Número de decalage’s | Duración mínima | Duración máxima | Promedio de duración | Duración total de comentario | Porcentaje de duración del comentario |
| Muestra 4 | 15 | 1,440 | 4,371 | 2,610 | 39,151 | 64% |
| Muestra 2 | 13 | 0,655 | 4,890 | 2,693 | 35,004 | 55% |
| Muestra 3 | 11 | 1,31 | 5,765 | 3,550 | 39,045 | 62% |
Leyenda tabla 8: Compilado de segmentos de decalageanalizados
Relación duración enunciado LSC/ enunciado LC
Se observó que algunas secciones de textos en LSC, por características visuales espaciales y gestuales (Modalidad VEG), demandan menos tiempo en enunciarse que su equivalencia formal en lengua castellana (Ver imagen 4 y 5).

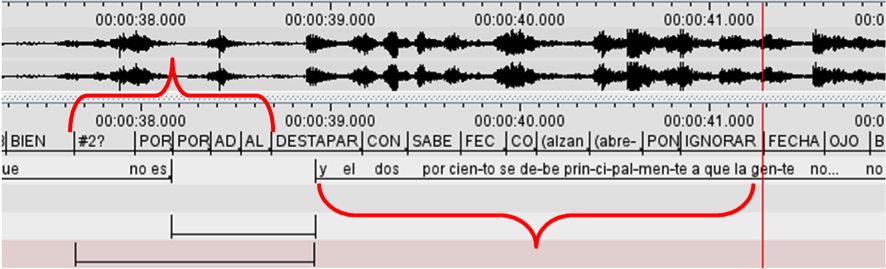
Como se muestra en las anteriores imágenes, las interpretaciones en lengua castellana superan el doble de la extensión de los textos origen en LSC. En la imagen 4, por ejemplo, se produce un enunciado que supera la tasa de velocidad de cualquier interpretación enunciada en lengua oral. El segmento de texto en lengua de señas compuesto por cinco señas dura apenas 1,02 segundos, es decir, cada seña se realiza en 0,2 segundos. La interpretación del mismo segmento se realizó en 2,4 segundos a una velocidad de 300 palabras por segundo (el doble de la rapidez de un discurso normal en lengua hablada).
Distribución de las pausas
Se observa una tendencia muy baja al realizar pausas en el discurso señado, algunos sordos prácticamente no hicieron pausas en el minuto de la muestra (0,2 y 0,4 segundos en el caso de las muestras 2 y 4 respectivamente), otros sólo se limitaron a realizar señas con movimientos más extensos, algunos de los cuales alcanzaron a lo sumo a durar un segundo. Se contó como pausa los segmentos de tiempo con manos en reposo o silencio acústico superiores a medio segundo[9].
El promedio de las pausas en LSC fue de 2,3 segundos. Es interesante este hecho porque en este caso de las muestras 2, 3 y 4, los textos se constituyen en textos de origen los cuales no tienen ninguna presión aparente por aumentar la velocidad.
Por otro lado, las pausas realizadas por el intérprete fueron de 14,8 segundos en promedio. ¿La razón?, parece que existe la tendencia del intérprete a normalizar su producción textual independientemente de la fuente original (Cfr. universales traductológicos; Baker, 2004). El intérprete pausa, así su interlocutor en lengua de señas no lo haga. Esto tiene sentido, en primer lugar, en términos fisiológicos; el intérprete necesita tomar aire para seguir hablando, mientras aparentemente el señante no necesita pausar para seguir haciendo señas, ya que los articuladores de la lengua de señas difieren del aparato respiratorio, asunto que no sucede en la lengua castellana (con el mismo aparato con el que se habla, se respira).
Habilidades de cierre y reducción
Ya que la relación de contenido de información en función del tiempo entre el TO en señas y el TT en español está a razón de 1:2, se percibe cierta tendencia del intérprete a realizar cierres semánticos, sintácticos y textuales, con el fin de optimizar su desempeño.
Como muestra en la Ilustración 6, mientras la producción en texto origen en señas dura 4,9 seg., la interpretación en lengua castellana dura 2,3 seg.Estas reducciones, son una constante en las muestras del presente estudio dada la rapidez del discurso; en el mejor de los casos se hicieron los cierres lingüísticos antes mencionados, sin embargo, en muchas ocasiones, la información sencillamente se omitió por olvido, no se alcanzó a verbalizar completamente, o no fue percibida por el intérprete. Aunque este ejercicio no pretendió evaluar la equivalencia del trasvase[10], se calcula por observación aproximada que la efectividad de la interpretación perfectamente no superó el 60 porciento de asertividad. De 5 enunciados, 2 fueron omitidos o mal interpretados.
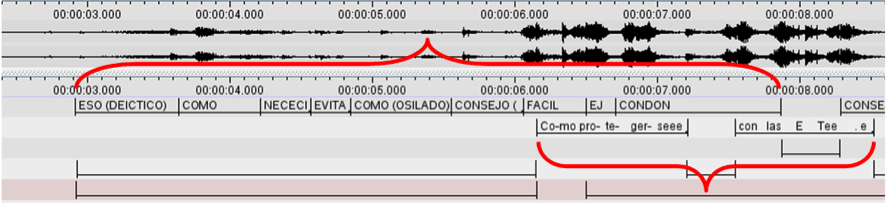
Decalage
El promedio de tiempo de retraso (decalage) para todas las muestras fue de 2,9 segundos una tasa relativamente baja en comparación con los datos de Cokely expuestos arriba en la tabla 5. Queda pendiente establecer de qué forma la tasa se debe a la suma de las deficiencias de la memoria a corto plazo y habilidades verbales del intérprete, la velocidad, el tipo de conocimiento contextual de las situaciones y el cansancio.
Recuperación de la información
Una tendencia observada en la muestras fue la aparente capacidad del intérprete de retomar un elemento semántico, supuestamente olvidado/perdido, e incorporarlo en un proceso de interpretación posterior. Se evidenciaron dos de estos fenómenos en las dos muestras que menos usaron pausas. (Muestras 2 y 4)
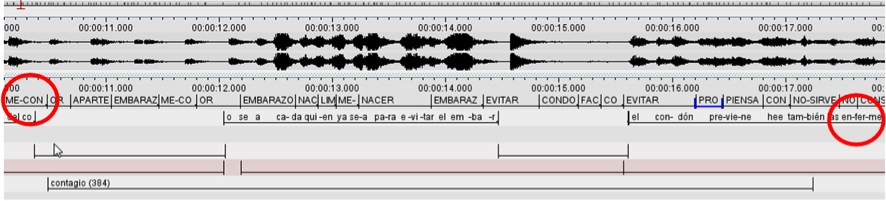
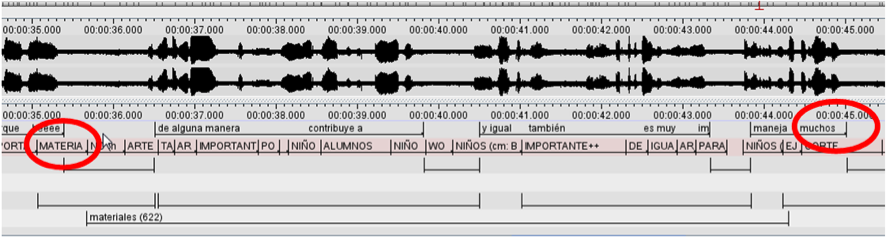
La recuperación podría definirse como la posibilidad que tiene el proceso de interpretación de tomar elementos recibidos del TO almacenados en la memoria a largo plazo e incorporarlos a la interpretación en un tiempo posterior (Fishberg, 1990).
En la muestra de recuperación 1, la seña me-contagia (0:10:03), es incorporada en términos semánticos después de la respectiva interpretación simultánea (00:12:00 – 00:14:00) en la expresión (00:17:06) en castellano “…previene hee también las enfermedades…”. La razón para argüir una recuperación en este caso, radica en el hecho que la interpretación es correcta, pero el informante nunca indicó la seña enfermedad. Al parecer, el intérprete construye enfermedades a partir de la recuperación del campo semántico de me-contagia.
Otro aspecto que es importante señalar es que la recuperación 2 (8, 6 Segundos después, muy cerca del umbral de retentiva que mostro el intérprete más hábil de la investigación de Cokely) se transformó en una sustitución, es decir, en una traducción equivocada. El elemento lingüístico enunciado en el segundo (00:35:00) en LSC era materia (asignatura) y fue interpretado como “materiales (para el arte)”, segundo (00:44:05). Este ejemplo nos podría sugerir los límites que tiene la memoria corto y a largo plazo, y la capacidad que tiene un intérprete para retener con exactitud cierta información en cierta cantidad de tiempo.
En suma, existe la posibilidad que este último ítem de muestras de recuperación, sea una falsa ilusión recreada por las muestras, o por la transcripción, ya que se utilizó un solo intérprete como informante. De modo que, existe el riesgo de establecer recuperaciones donde sólo hay información que pertenece a los supuestos contextuales de la conversación (Speber & Wilson, 1986 (1994)). Dicha información recuperada no sería estrictamente fruto de un proceso específico de la interpretación simultánea sino de la construcción de significado que pertenece a cualquier comunicación humana. Existe la posibilidad de que los elementos recuperados fueran “dados” por el conocimiento enciclopédico del mundo del intérprete (esto es los supuestos contextuales de la situación comunicativa) y no por su memoria operativa. Sin embargo, también existe la posibilidad que este aparente fenómeno nos esté indicando algún aspecto del proceso de interpretación que desconozcamos hasta el momento. Queda patente la necesidad de ahondar en las recuperaciones como una técnica/proceso de la interpretación LSC/castellano en investigaciones posteriores.
Potencialidades del ELAN para describir el discurso en LSC interpretado al español.
El ejercicio de la mesa de trabajo ELAN permite esbozar algunos campos en los cuales la transcripción de interpretaciones de lengua de señas podría ampliar la investigación en el discurso en LSC y otros campos relacionados.
Descripción de elementos del discurso de la LSC.
Como el ELAN permite sistematizar material multimedia, las transcripciones con dicho programa permitirían iniciar un análisis riguroso de los elementos constitutivos del discursivo en LSC. Dichos análisis se ha realizado en otros países en los últimos años utilizando algunas categorías útiles, aunque poco articuladas a un hipotético esquema teórico comprehensivo de análisis del discurso para las lenguas señadas[11]. Algunas de la categorías más nombradas son: los espacios mentales sucedáneos (surrogates), las boyas (bouys), los sectores simbólicos(tokens), verbos descriptivos (depicting verbs) (Liddell, 2003), la concordancia verbal (verb agreement) (Padden, 1988), los cambios del cuerpo (body shifting) (Winston, 1999) y el diálogo y la acción construida (DCAC, por sus siglas en inglés)(ver Roy, 1989; Metzger, 1995; aplicando la propuesta de Tannen, 1989).Gran parte de la dispersión conceptual en torno a los elementos discursivos en de las lenguas señadas se debe a la compleja interacción entre el gesto y los signos lingüísticos en la modalidad visual, espacial y gestual (VEG).[12]
Procedemos a mostrar algunos ejemplos que evidencian el potencial del ELAN para determinar elementos discursivos de la LSC. Nos basaremos en la propuesta de Dudis (2011)que, en el marco conceptual de la lingüística cognitiva y la propuesta de Roy (2011),agrupa los principales elementos discursivos de las lenguas señadas en una nueva categoría que estaría a la par y estrechamente relacionada con las tradicionales coherencia y cohesión: el depicting.

En el ejercicio de transcripción, se pudieron identificar algunos de dichos elementos lingüísticos en la LSC.
Depictions abstractos
Los depictions abstractos son aquellas representaciones visuales que simbolizan el espacio con información lingüística en formas particulares: como una línea imaginaria de tiempo horizontal, como un plano calendario (x,y) frente al señante o como sectores determinados (tokens). Los tokens son sectores del espacio frente al señante que codifican contenido lingüístico específico con miras a la cohesión textual. En el ejemplo de la Imagen 10, la seña arte es codificada en el sector del espacio a la izquierda del señante cuando se realiza la seña que-es(Ver detalle Imagen 11).
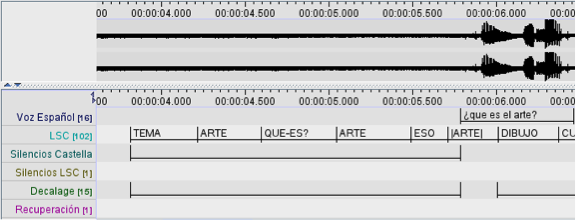

En la LSC existen pronombres y deícticos, como la seña que-es(deíctico interrogativo, (Oviedo, 2001))que tienen un comportamiento variable (gradiente, en términos de Liddell, 2003) muy parecido a los verbos demostrativos de la forma[13]→x o →y (e.g. ayudar→x (ayudar infinitivo), ayudar→y (ayudar a alguien)). Lo anterior significa que la dirección a la que apuntan dichas señas no determina una locación ‘morfo-fonológica’ específica en el espacio, sino representa un componente gestual superpuesto con elementos fonológicos (esto es, la configuración y la orientación manual). De este modo, la seña que-es necesariamente no implica la construcción de tokens. Sin embargo, en el caso de la imagen 10, la seña que-es es realizada hacia una locación específica que codifica la seña arte. Queda patente la simbolización cuando se realizan después otras señas hacia dicho espacio a través de la Muestra 4 brindando cohesión al texto en LSC, tal como lo muestra la Imagen 12.

Depictions a escala
Los depitctions a escala incluyen una amplia cantidad de señas que representan visualmente entidades, incorporando gran cantidad de información sobre la forma de las entidades (i.e. clasificadores, (Aikhenvald, 2000) (Emmorey, 2003)), los movimientos (i.e. verbos) y la disposición topológica general de la ‘escena’ representada en el enunciado. Este tipo de representaciones, quedan patente en algunos verbos como el de la imagen 13

Depictions a tamaño real
La LSC tiene la posibilidad de incorporar representaciones en el discurso utilizando el cuerpo: el rostro y la inclinación-rotación del torso (|cuerpo|[14] dinámico), alguna locación específica del cuerpo como territorio (|cuerpo| estático), y el cuerpo como punto de observación panorámica (vantage point). La transcripción a través del ELAN permite analizar con detalle estos elementos discursivos de la LSC que requieren del video. Por ejemplo, en la imagen 10, puede no ser tan claro que la seña arte (0:05:300) es un nombre, mientras que |arte| (0:05:833) es una compleja depiction generada por la combinación de espacios mentales (surrogates, en términos de Liddell, 2003). La diferencia se aprecia en la imagen 14.
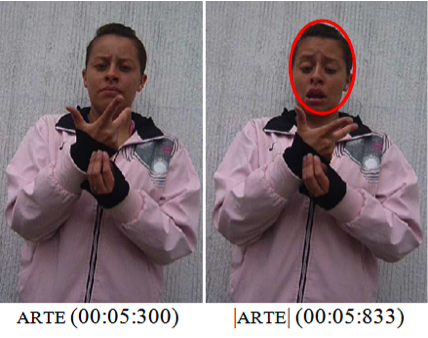
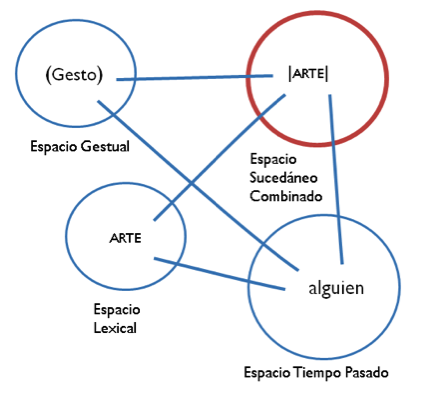
El ejemplo de la imagen 14 contiene un gesto que se utiliza en LSC para ilustrar (depict) a una persona hipotética, que en un tiempo hipotético desarrolla una acción. De esta forma, arte sería un nombre en LSC, mientras que |arte| significaría “alguien diciendo ‘arte’ en un tiempo determinado”. Lo anterior se puede esquematizar como lo muestra la imagen 15.
El anterior recuento de elementos discursivos de modalidad VEG permite percibir la utilidad del ELAN para la transcripción de la LSC. Sólo con un instrumento que integre video y herramientas para la notación digital, es posible dar cuenta de elementos lingüísticos como el depicting.
Por otro lado, los beneficios del ELAN no se suscriben sólo al uso del video. El mismo programa tiene la capacidad de sistematizar los valores que son transcritos en términos de tiempo, por lo que puede arrojar datos estadísticos que son sumamente útiles si se desea ver los textos en términos globales y cuantitativos. Por ejemplo, el ejercicio realizado en la Mesa ELAN, que transcribió textos expositivos en LSC en el contexto universitario, estructuralmente tiene diferencias marcadas con otros tipos de textos en LSC, como un texto narrativo (Barreto & Cortés, 2012) Las diferencias cuantitativas develadas con ayuda del ELAN, pueden apreciarse en la tabla 9.
Tabla 9
| Discurso Narrativo(Barreto & Cortés, 2012) | Discurso Expositivo(MesaELAN) | |||
| Duración de Señas | (Variedad Bogotana) | (Variedad Costeña) | Muestra 2 | Muestra 3 |
| Promedio | 1,066s | 1,104s | 0,380s | 0,415 |
| Mediana | 0,858s | 0,957s | 0,320s | 0,330 |
| Seña/minuto | 57,7 | 53,1 | 159 | 130 |
| Duración Mínima | 0,099s | 0,165s | 0,114s | 0,99 |
| Duración Máxima | 4,13s | 5,48s | 1,68s | 2,86s |
Concurrencias Bimodales, Interpretación Intermodal
El ELAN resulta útil para describir la interpretación de lengua de señadas dada la capacidad multimodal que soporta el software. Como en dicho tipo de interpretación existen momentos en los que al mismo tiempo en el que se usa el castellano (auditivo-oral), se puede usar la LSC (VEG), es decir, pueden traslaparse o superponerse las modalidades (lo que podríamos llamar como ‘concurrencias bimodales’), uno de los autores del presente artículo considero pertinente nombrar el fenómeno como traducción/interpretación bimodal (Barreto A. G., 2010).
Sin embargo, existen algunas razones por las cuales se puede abandonar esta y otras categorías similares. El término bimodal suele utilizarse para nombrar un método que se empezó a utilizar en Estados Unidos en la educación de los Sordos, el cual consistía en hablar el inglés al mismo tiempo en el que se hacían las señas. Ese método se enmarcó en una aplicación distorsionada de la filosofía antropológica conocida como la Comunicación Total (Lane, 1999 (1992)) (Lane, Hoffmeister, & Bahan, 1996) que fue ampliamente difundida en el mundo. También se ha hablado de bilingüismo bimodal en los niños oyentes que aprenden simultáneamente la lengua de señas de sus padres como lengua materna y el inglés por familiares oyentes y en la escuela (Bishop & Hicks, 2009). El sentido en que se utiliza bimodal en este tema difiere de sentido dado en Comunicación Total.
Hablar de traducción/interpretación bimodal podría sugerir que el intérprete o traductor de LSC, habla el castellano y la LSC al mismo tiempo, asunto que, si bien, resulta complicado hacerlo con el mismo mensaje (como se hizo en la Comunicación Total), resulta prácticamente imposible hacerlo en términos de traducción e interpretación. Si quisiéramos referirnos al fenómeno en términos de modalidad, en lugar de bimodal, sería más preciso referirse a él como intermodal; traducción intermodal e interpretación intermodal (de forma separada, ya que la relación entre modalidades sería muy distinta en traducción en tanto que en interpretación).Sin embargo, investigaciones recientes (Janzen, 2005) (Brunson, 2011) (Napier, Mckee, & Goswell, 2010) muestran que las tendencias no van encaminadas en la dirección de nombrar a los fenómenos como intermodales.
La razón es sencilla. Toda vez que llamamos a dichos procesos traslatorios como, traducción o interpretación intermodal, bimodal, intersemiótica, traducción e interpretación de lengua (o lenguaje) de señas o traducción e interpretación de lengua de signos (como tradicionalmente es usado sólo en España). Reforzamos el imaginario colectivo ante la comunidad académica hispanohablante de que las lenguas señadas, no son lenguas naturales sino códigos, sistemas visuales o lenguajes[15] (Rodriguez de Salazar, Monroy, Galvis, & Pabón, 2012). Sin embargo, los Sordos del país tienen una lengua específica, la cual es llamada por ellos mismos por nombre propio: LSC. En ese sentido las actividades traslatorias debería llamarse con justicia: Interpretación LSC – castellano o Traducción LSC – castellano, tal cual como se hace con la traducción e interpretación de lengua orales (e.g. Traducción castellano – inglés, francés – alemán etc.).
Conclusiones
El software ELAN presenta novedosas oportunidades de aplicación tanto para los espacios de fortalecimiento de la LSC para usos académicos de la Universidad como para la optimización y evaluación del servicio de interpretación LSC – castellano.
La mesa de trabajo ELAN podría consolidarse como un espacio de investigación en la Universidad que propenda por la exploración de la interpretación de lengua de señas en contextos universitarios. Con los corpus de interpretación de lengua de señas, la mesa podría avocarse, no solo en describir las tipologías de supuestos errores de interpretación, como ya lo han hecho otros investigadores (Cokely, 1992; Napier, 2002; Russell, 2002), sino, además, enfocarse en las razones por las cuales se cometen dichos errores de interpretación específicamente en el contexto universitario. Por otro lado, las transcripciones de discursos en LSC y discursos en castellano, podrían ser sumamente útiles para describir los procesos discursivos en las lenguas implicadas así como las fases y los procesos cognitivos de interpretación. Este tipo de descripciones, facilitaría el diseño e implementación de materiales didácticos destinados a la formación y cualificación de intérpretes así como los procesos planeación lingüística y enseñanza-aprendizaje de la LSC entre otras actividades.
Bibliografía
Aikhenvald, A. (2000). Classifiers: A Typology of Noun Categorization Devices. Oxford: Oxford University Press.
Barreto, A. G. (2010). Hacia una Traducción Bimodal. Mutatis Mutandi: Revista Latinoamericana de Traductología, 3(2).
Barreto, A., & Cortés, Y. (2012, Junio 28). Dos variedades sociolingüísticas: analisis fono-morfológico y discursivo. Diplomado en Planeación Lingüística. Bogotá: Universidad Nacional de Colombia.
Bishop, M., & Hicks, S. L. (Eds.). (2009). Hearing, Mother Father Deaf: Hearing People in Deaf Families. Washington: Gallaudet University Press.
Brunson, J. L. (2011). Video Relay Service Interpreters. Washington: Gallaudet University Press.
Cerney, B. (2005). Interpreting Hand Book. Cleveland : Hand & Mind Publishing.
Cokely, D. (1992). Interpretation: a Sociolinguistic Model. Burtonsville, MD: Linstok Press.
Dudis, P. (2011). The body in scene: depictions. In C. Roy (Ed.), Discourse in Signed Languages. Washington: Gallaudet University Press.
Emmorey, K. (2003). Perspectives on Classifier Constructions in Sign Languages. Mahwah, NJ: Lawrence Erlbaum Associates.
Fauconnier, G. (1994). Mental spaces: Aspects of meaning construction in natural languages. Cambridge: Cambridge University Press.
Fishberg, N. (1990). Interpreting: An Introduction. Washington: Registry of Interpreters for the Deaf, Inc.; Revised edition.
Gerver, D. (1976). Empirical Studies of Simultaneus Interpretation: a review and model. In Brislin, Translation: aplications and research (pp. 165-207). New york: Gadner Press.
Janzen, T. (2005). Introduction to the theory and practice of signed language interpreting. In Topics in Signed Language Interpreting: Theory and Practice (pp. 3 -24). Amsterdam – Philadelphia: John Benjamins.
Janzen, T. (Ed.). (2005). Topics in Signed Language Interpreting: Theory And Practice. London: John Benjamins Company Publisher.
Lane, H. (1999 (1992)). The mask of the benevolence: disabling the Deaf comunity (2 ed.). San Diego: DawnSign Press.
Lane, H., Hoffmeister, R., & Bahan, B. (1996). A Journey into the Deaf-World. San Diego: DawnSign Press.
Leeson, L. (2005). Making the effort in simultaneous interpreting: Some considerations for signed language interpreters. In T. Janzen (Ed.), Topics in Signed Language interpreting (pp. 51 – 68). Amsterdam – Philadelphia: John Benjamins.
Liddell, S. (2003). Grammar, gesture and meaning in american sign language. Cambridge: Cambridge University Press.
Metzger, M. (1995). The paradox of neutrality: a comparsion of interprete’s goals with the reality of interactive discourse. Washington DC: Tesis doctoral inédita.
Napier, J. (2002). Sign language interpreting:Linguistic coping strategies. Gloucestershire: Douglas McLean.
Napier, J. (2009). Sign International Perspectives on sign language interpreter education. Washintong: Gallaudet University Press.
Napier, J., Mckee, R., & Goswell. (2010). Sign Language Interpreting: Theory and practice in Australia and New Zealand (2 ed.). Syndey: The Federation Press.
Oviedo, A. (2001). Apuntes para una gramática de la lengua de señas colombiana. Bogotá: INSOR – UNIVALLE.
Padden, C. (1988). Interaction of Morphology and Syntax in American Sign . New York and London: Garland Publishing, Inc.
Paneth. (1957). A Investigation into Conference Interpreting. London: Tesis MA no publicada, University of London.
Rodriguez de Salazar, N., Monroy, E., Galvis, R., & Pabón, M. (2012). Manos y Pensamiento: Mirada a los lenguajes de los Sordos. Bogotá: Universidad Pedagógica Nacional.
Roy, C. (1989). Features of Discourse in an American Sign Language Lecture. In C. Lucas, The Sociolingüístic of deaf communities (pp. 443-457). San Diego: Academia Press.
Roy, C. (Ed.). (2011). Discourse in Signed Languages. Washintong: Gallaudet University Press.
Russell, D. (2002). Interpreting in legal Contexts:Consecutive and Simultaneous Interpretation. Burtonsville, MD: Linstok Press.
Seleskovitch, D. (1978). Interpreting for International Conference. Washington, DC: Pen and Booth.
Speber, D., & Wilson, D. (1986 (1994)). La relevancia. (E. Leonetti, Trans.) Madrid, España: Visor.
Tannen, D. (1989). Talking Voices: Repetition, dialogue, and imagery in conversational discourse. Cambridge: Cambridge University Press.
Taub, S. F. (2001). Language from the Body: Iconicity and Metaphor in American Sign Language. Cambridge: Cambridge University Press.
Tovar, L. (2010). La creación de neologismos en la lenga de señas colombiana. Lenguaje, 38(2), 237 – 312.
Wilcox Perrin, P. (2000). Metaphor in American Sign Language. Washington: Gallaudet University Press.
Wilcox, S., & Shaffer, B. (2005). Towards a cognitive model of interpretating. In T. Janzen (Ed.), Topics in Signed Language Interpreting: Theory And Practice (pp. 27 – 51). London: John Benjamins.
Winston, E. (Ed.). (1999). Storytelling and Conversation: Discourse in Deaf Communities. Washington: Gallaudet University Press.
Notas
[*] Acerca de los autores: Alex G. Barreto M. (abarretoz@gmail.com). Sonia Margarita Amores (cucurucu87@gmail.com). Mesa de Trabajo ELAN, Proyecto Manos y pensamiento, Calle 72 #11-86 Edificio C, Oficina 202. Teléfono: 3471190, Ext. 437, Universidad Pedagógica Nacional
[1]Usamos Sordo (con mayúscula) para denotar una identidad lingüística y cultural en torno a los usuarios nativos de la lengua de señas colombiana (LSC).
[2]Sitio web:http://www.lat-mpi.eu/tools/elan/
[3]Se conoce como decalage o lag time al tiempo de desfase que se utiliza en interpretación simultánea entre la emisión de un texto hablado en LO y la producción de la interpretación en LT. El uso del decalage es vital para contextualizar la interpretación simultánea, ya que es imposible predecir con certeza lo que un hablante va enunciar.
[4]evitar es una glosa en lengua de señas. Las glosas son palabras en castellano que se escriben en versalitas, las cuales intentan hacer un acercamiento al significado de una seña en LSC, por lo que no deben entenderse como traducciones.
[5] Agradecemos cordialmente la disposición de los estudiantes Nelson Cortes y Kelly Roca por permitirnos amablemente la filmación de su discurso en LSC para este estudio.
[6]Para simplificar el cuadro omitimos todos los subprocesos detallados en el modelo.
[7]Persiste la discusión sobre si una seña se corresponde a una palabra o en realidad a una frase. Al respecto ver comentario de Tovar (2010).
[8]Hasta el momento, la investigación en los géneros discursivos de las lenguas de señadas ha sido muy escasa (Roy, 2011)
[9]Este criterio lo definen la mayoría de investigaciones ya que de otro modo la tasa de silencios se ve distorsionada significativamente.
[10]Evaluar la equivalencia del trasvase, supondría asumir un modelo traductológico y un tipo de test estadístico como el usado por Debra Russel en contextos legales, el Chi-Square Test (Russell, 2002)
[11]Utilizamos la expresión lenguas señadas como una forma genérica para referirnos a las lenguas de señas (ASL, LSC, LSA etc.) como una categoría alterna a lenguas orales o “habladas”, siguiendo la propuesta expuesta por Janzen (Introduction to the theory and practice of signed language interpreting, 2005, pág. 19), tradición ya adoptada por varios investigadores anglohablantes.
[12]Con referencia a la discusión sobre la interacción del gesto y la modalidad VEG como componentes constitutivos (verbales) de las lenguas señadas y no como simples elementos paralingüísticos (no-verbales) ver Liddell (2003).
[13]Utilizamos la terminología de Liddell (2003) para la nominación morfológica de los verbos en lengua de señas. Por razones de espacio no colocamos todas las imágenes de las señas correspondientes.
[14]Como lo mencionamos anteriormente, utilizamos la notación de Liddell (2003) para señalar depictions de cuerpo. La notación (|x1|) ha sido sugerida por otros investigadores (Wilcox Perrin, 2000; Dudis, 2011; Taub, 2001) y denota que dichas representaciones corresponden a espacios mentales combinados sucedáneos (surrogates). Para revisar la teoría cognitiva de los espacios mentales ver, Fauconnier (1994).
[15]Una categoría apropiada, pero que resulta sumamente amplia y difusa para referirse a la lengua señada del país, que tiene un nombre específico: la LSC.
Sé el primero en comentar